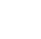Erasure Coding vs Replication Factor 3
Published on July 3, 2026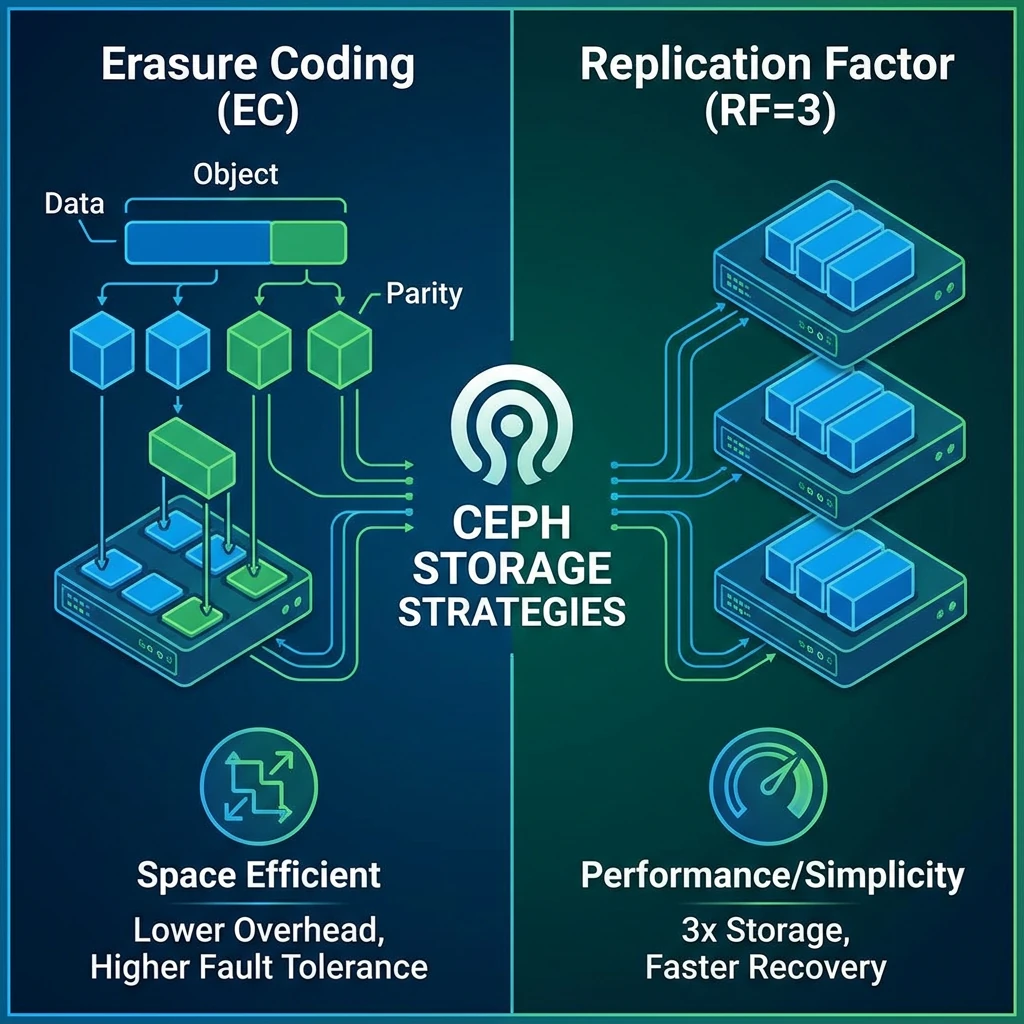
หนึ่งในคำถามที่มักจะเกิดขึ้นในขณะที่ตั้งค่าเกี่ยวกับ Software Defined Storage โดยใช้ Ceph คือ เราจะเลือกใช้ หลักการกระจายข้อมูลแบบไหน จะใช้ Replication Factor หรือว่า Erasure Coding ดีกว่ากัน บทความวันนี้เราจะพาท่านไปพบกับคำตอบกัน
ก่อนอื่นต้องบอกว่า สำหรับค่าเริ่มต้น หากเราไม่ปรับเปลี่ยนเลย เราจะพบว่า Ceph นั้นมีการต้้งค่าโดยใช้ Replication Factor =3 ทั้งนี้นั้นนั้นมันมีความหมายเชิงการแนะนำอยู่พอควร เพราะว่า การใช้ Replication Factor นั้นมีผลดีคือ ประสิทธิภาพดีกว่า ความหน่วงต่ำกว่า และ การรองรับความผิดพลาดนั้นทำได้ง่ายกว่า
งั้นเรามาเปรียบเทียบเชิงตารางกันเลย
| หัวข้อ | Replication (RF=3) | Erasure Coding (EC) |
|---|---|---|
| ประสิทธิภาพด้านเนื้อที่ | ใช้ได้ 33% จากทั้งหมด | ใช้ได้ 60–90% |
| ประสิทธิภาพการอ่าน | ✅ ดีเยี่ยม | ⚠️ ดี |
| ประสิทธิภาพการเขียน | ✅ ดีเยี่ยม | ❌ ช้ากว่า |
| การใช้ CPU | ✅ ต่ำ | ❌ สูง |
| การใช้เน็ตเวิร์ก | ✅ ต่ำกว่า | ❌ สูงกว่า |
| การกู้คืน | ✅ เร็วกว่า | ❌ ช้ากว่า |
| ดีสำหรับ | VM disks, databases | การแบ็คอัพ การสำรอง และ object storage |
จากหัวข้อดังกล่าวข้างต้น เรามาขยายความกันในแต่ละส่วน
- โดยปกติแล้ว VM นั้นจะทำการเขียนแบบสุ่มด้วยข้อมูลเล็กๆ : ปกติแล้ว VM นั้นจะเขียนข้อมูล ขนาม 4KB,8KB,16KB, Metadata, Journals และ Database Transactions และการเลือกเทคนิตการกระจายข้อมูลแบบ replication นั้นจะทำการเขียนง่าย เช่น VM มีการเขียนข้อมูล 4KB ข้อมูลชุดดังกล่าวก็จะถูกกระจายไปยัง OSD เท่ากัน โดยง่าย ไม่ได้มีเงื่อนไขอะไรซับซ้อน
แต่หากเราเลือกแบบ Erasure Coding ข้อมูลเดียวกันที่มีขนาด 4KB และเราเลือกแบบ EC 4+2 Block ของข้อมูล จะถูกแตกออกไปเป็น Data 1-4 และมี Parity 2 เราจะได้ทั้งหมด 6 chunks เมื่อเป็นเช่นนั้นแล้ว การอัพเดทข้อมูล แม้ว่ามันไม่ได้เยอะมาก แต่มันจะเท่ากับ การอ่าน chunks เดิมขึ้นมา คำนวณ parity bit ใหม่ และ เขียน chunk กลับเข้าไป ซึ่งเพียงแค่นี้ท่านก็จะเห็นแล้วว่ากระบวนการนั้นไม่ได้ง่ายเลย - การ Rebuild หากเกิดดิสก์เสีย : ยกตัวอย่างกรณีที่โหนดตัวหนึ่งมีปัญหา เมื่อมีดิสก์ใหม่ มันก็เท่ากับการ คัดลอกข้อมูลเดิมไปยังดิสก์ก้อนใหม่ แต่ในขณะเดียวกัน Erasure Coding จะต้องทำการอ่าน Chunk หลายต่อหลายตัวและทำการคำนวณ parity ใหม่ และ ทำการเขียนใหม่ การอ่านจะใช้เวลานานขึ้นจากหลายโหนด และ แน่นอนการคำนวณต้องใช้ CPU เยอะด้วยเช่นกัน
- ระบบฐานข้อมูลนั้นไม่ค่อยเหมาะกับ Erasure Coding เลย : ไม่ว่าจะเป็นฐานข้อมูล PostgreSQL, MySQL, SQL Server หรือ Oracle จะมีการเขียนเล็กๆ อยู่ตลอดเวลา แต่ด้วยเหตุผลที่บอกไปก่อนหน้า มันจะทำให้ CPU ต้องใช้เยอะในกรณี และ ระบบฐานข้อมูลไม่เหมาะเลยหากท่านใช้ EC
- ระหว่างการเกิดความเสียหายในโหนด : หากท่านใช้ Replication Factor แล้ว การเสีย 1 โหนดไปไม่ใช่ปัญหา เพราะว่าท่านยังมี ข้อมูลจะถูกอ่านจากที่เหลือ อีกสองโหนด แต่สำหรับ Erasure Coding แล้ว chunk ที่หลายไป ซึ่งอาจจะอยู่ในโหนดที่มีปัญหา จะต้องทำการถูกสร้างใหม่ และ นั่นคือการนำ chunk ที่เหลือและ parity มาคำนวณ ซึ่งใช้ทั้ง CPU และ network traffic
หวังว่าบทความนี้คงจะช่วยสร้างความกระจ่างให้ท่านได้ และ เลือกใช้การจัดการดิสก์ที่ถูกต้องบน Ceph กรณีมีคำถาม หรือ ข้อสงสัย เกี่ยวกับ Proxmox VE หรือต้องการซื้อ subscription สามารถติดต่อแผนกเซลล์ของเราได้ที่ Line OA : @avesta.co.th หรืออีเมล์ [email protected]
Erasure Coding vs Replication Factor 3

Software Performance and Load Testing Services

Smart Energy Management for Apartments, Condominiums and Residences
Tailscale Subnet Routers

MinIO vs Garage S3 vs Ceph RGW