การอ่านค่าและตีความค่าด้านประสิทธิภาพใน Proxmox VE 9
Published on March 11, 2026
ทำความเข้าใจเกี่ยวกับการวัดค่าต่างๆ ใน Proxmox VE 9
Proxmox VE 9 เป็นแพลตฟอร์ม virtualization แบบโอเพ่นซอร์สที่ทรงพลัง ซึ่งรวมเอา ความสามารถในการจัดการสิ่งเหล่านี้เข้ามาร่วมกัน
- KVM virtualization
- LXC containers
- Software-defined storage เช่น ZFS และ Ceph
เพื่อให้ cluster ของคุณทำงานได้ เสถียรและตอบสนองได้ดี คุณจำเป็นต้องเข้าใจว่า metrics ต่าง ๆ ของ Proxmox หมายถึงอะไร และควรตีความอย่างไร
คู่มือนี้จะอธิบาย metrics ที่สำคัญทั้งหมด เช่น
- CPU
- Memory
- I/O pressure
- Storage performance
Proxmox Metrics คืออะไร
Proxmox จะทำการเก็บ ค่าประสิทธิภาพของระบบ (metrics) อย่างต่อเนื่องจาก
- Linux kernel
- KVM hypervisor
- ระบบ storage
Metrics เหล่านี้ช่วยให้คุณเข้าใจข้อมูลเกี่ยวกับ
- สุขภาพของ Node (CPU, RAM, I/O, swap)
- ประสิทธิภาพของ VM และ container
- การสื่อสารภายใน cluster
- พฤติกรรมของ storage เช่น ZFS หรือ Ceph
คุณสามารถดู metrics เหล่านี้ได้จาก
- Proxmox Web GUI
- Command line
- เครื่องมือ monitoring ภายนอก เช่น Nagios หรือ Grafana หรือเครื่องมืออื่นๆ ซึ่งเป็น 3rd party monitoring software
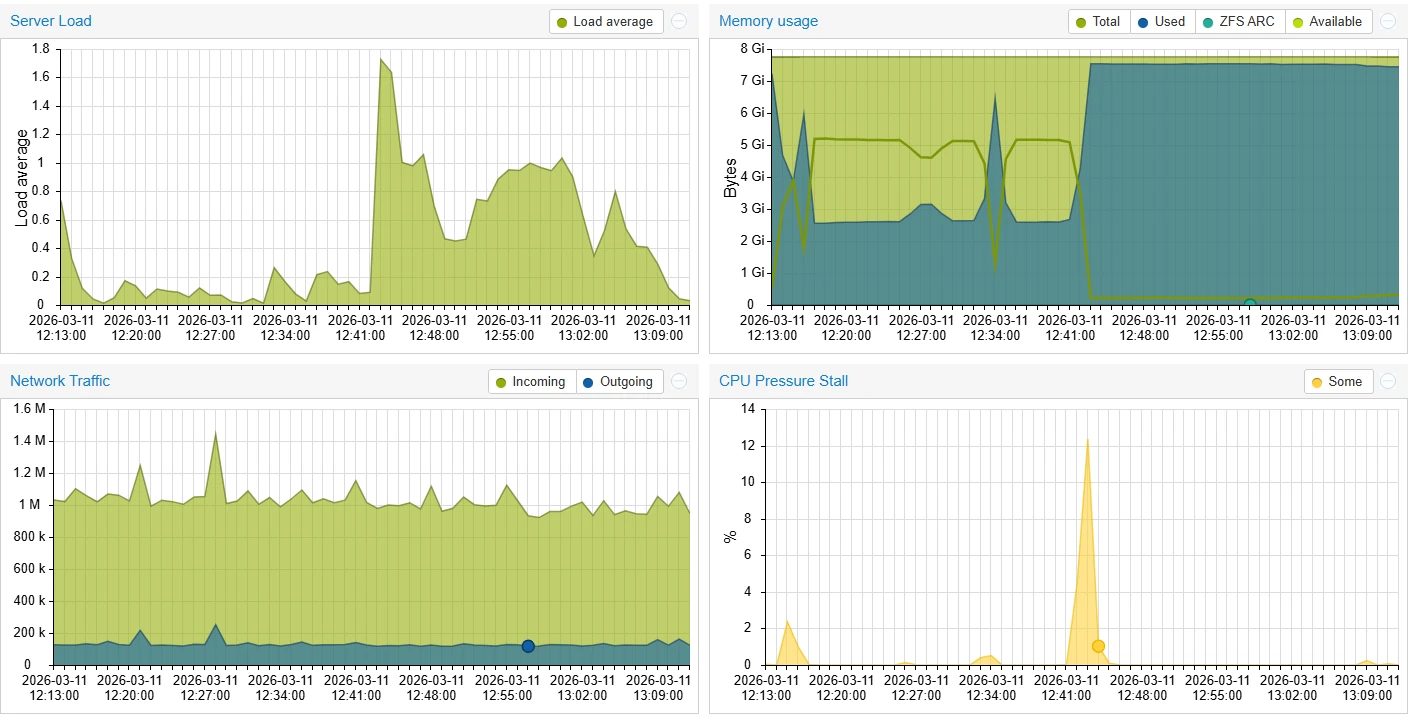
Node-Level Metrics ใน Proxmox VE 9
Metrics กลุ่มนี้แสดง สุขภาพโดยรวมของเครื่อง host (หรืออาจจะเรียกว่า node)
สามารถดูได้ที่
Datacenter → Node → Summary / Metrics
ซึ่ง Node ก็คือชื่อโหนดที่ท่านตั้งไว้
หรือใช้คำสั่ง
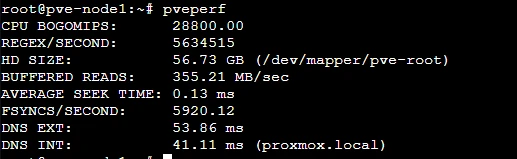
pveperf
| Metric | คำอธิบาย | ค่าที่เหมาะสม | หมายเหตุ |
|---|---|---|---|
| CPU Usage (%) | การใช้ CPU รวมทุก core | <70% ต่อเนื่อง | รวม overhead ของ KVM |
| IO Delay (%) | เวลาที่ CPU ต้องรอ disk I/O | <5% | ค่าสูงแสดงว่าดิสก์เป็น bottleneck |
| System Load Average | จำนวน process ที่กำลังทำงานหรือรอ | ≤ จำนวน CPU cores | สูงเกินแปลว่า CPU หรือ I/O ติดคอขวด |
| Memory Usage (%) | RAM ที่ OS, VM และ ZFS ARC ใช้ | <80% | ARC อาจใช้ RAM จำนวนมาก กรณีใช้ ZFS |
| Swap Usage (%) | swap ที่ถูกใช้ | 0–10% | ใช้ต่อเนื่องแปลว่า RAM ไม่พอ |
| Network (In/Out) | bandwidth ของ NIC หรือ bridge | — | ใช้ดู traffic spike |
| Uptime | เวลาตั้งแต่ reboot ครั้งล่าสุด | — | บอกถึงเสถียรภาพของระบบ |
Disk และ Storage Metrics (ZFS, LVM, Ceph)
ประสิทธิภาพของ storage ส่งผลโดยตรงต่อ ความเร็วของ VM
สามารถดู metrics ได้ที่
Datacenter → Storage → Summary
หรือใช้คำสั่ง
zpool iostat -v 1
iostat -x 1
pvesm status
| Metric | ความหมาย | ค่าเหมาะสม | หมายเหตุ |
|---|---|---|---|
| Read/Write Throughput | ความเร็วการรับส่งข้อมูล | — | บอก workload |
| IOPS | จำนวน I/O ต่อวินาที | ยิ่งสูงยิ่งดี | ขึ้นกับชนิด disk |
| Latency | เวลาหน่วงของ I/O | <5ms SSD / <20ms HDD | ตัวชี้วัด storage ช้าที่สำคัญ |
| ZFS ARC Size | ขนาด read cache ของ ZFS | — | ช่วยเพิ่ม read performance |
| ZIL/SLOG Activity | การทำงานของ sync write log | — | ควรใช้ SLOG แยกสำหรับ NFS หรือ database |
| Fragmentation | การแตก fragment ของ pool | <50% | สูงเกินจะทำให้ performance ลด |
การทำความเข้าใจ I/O Pressure Stall
ตั้งแต่ Linux kernel 5.x เป็นต้นมา Proxmox รองรับ Pressure Stall Information (PSI) ซึ่งค่าดังกล่าวนั้นจะแสดงว่า process ต้อง รอนานแค่ไหนเพราะ resource ไม่พอ
ประเภทของ PSI
| Type | File | ความหมาย |
|---|---|---|
| CPU Pressure | /proc/pressure/cpu | รอ CPU |
| Memory Pressure | /proc/pressure/memory | รอ memory reclaim |
| IO Pressure | /proc/pressure/io | รอ disk I/O |
ตรวจสอบด้วย
cat /proc/pressure/io
ถ้า
avg10 > 10–15%
แปลว่าเกิด I/O bottleneck
มักเกิดจาก
- ดิสก์ช้า
- ZFS pool overload
- sync write จำนวนมากพร้อมกัน ทำให้เกิดคอขวด
Virtual Machine และ LXC Container Metrics
VM และ container แต่ละตัวมี metrics ของตัวเอง
ดูได้ที่
VM → Summary
หรือ
qm status <vmid> --verbose
| Metric | ความหมาย | สิ่งที่บอก |
|---|---|---|
| CPU Usage | CPU ที่ VM ใช้ | สูงแปลว่า workload หนัก |
| Memory Usage | RAM ที่ VM ใช้ | ใช้ตรวจ memory leak |
| Disk Read/Write | throughput ของ storage | บอก workload ของ disk |
| IOPS | จำนวน I/O | การอ่านเขียนของดิสก์ต่อวินาที |
| Network Traffic | network traffic ของ vNIC | ใช้ monitor bandwidth |
| Ballooning | การปรับ RAM แบบ dynamic | reclaim memory |
| Uptime | เวลาที่ VM ทำงาน | ใช้ตรวจ reboot |
Cluster Metrics และ Quorum
เสถียรภาพของ cluster ถูกวัดผ่าน Corosync เพราะมันคือตัวสื่อสารระหว่างโหนด
ดูได้ด้วยคำสั่ง
pvecm status
corosync-cfgtool -s
| Metric | ความหมาย | ค่าเหมาะสม |
|---|---|---|
| Quorum Status | cluster มี majority vote หรือไม่ | ต้องเป็น Yes |
| Vote Count | จำนวน node ที่มี vote | ควรใช้เลขคี่หรือ QDevice |
| Cluster Latency | latency ระหว่าง node | <2 ms |
| Link Errors | packet loss | ควรเป็น 0 |
ถ้า cluster มี 2 nodes แล้ว node หนึ่งล่ม
cluster จะ เสีย quorum เว้นแต่จะมี QDevice ซึ่งถูกคำนวณตามที่กำหนด
คำสั่ง Monitoring ที่สำคัญและมีประโยชน์มากในการทำงาน
| Tool | ใช้ทำอะไร | Command |
|---|---|---|
| pveperf | ตรวจ performance node | pveperf |
| top / htop | ดู CPU และ memory แบบ realtime | htop |
| zpool iostat | ดู throughput ของ ZFS | zpool iostat -v 1 |
| iostat | ดู disk stats | iostat -x 1 |
| arcstat.py | ตรวจ ZFS ARC cache | arcstat.py |
| pvecm status | ดู cluster quorum | pvecm status |
วิธีวิเคราะห์สถานการณ์ที่พบบ่อย
| อาการ | สาเหตุที่เป็นไปได้ | Metric ที่ควรดู |
|---|---|---|
| VM ช้า | Disk I/O bottleneck หรือคอขวด | IO delay / PSI |
| Backup ช้า | Storage latency สูง | zpool iostat |
| Memory สูง | ZFS ARC ใช้ RAM มาก กรณีเปิดใช้งาน ZFS | arcstat |
| Cluster ไม่มี quorum | Node down หรือ latency สูงเกิดอาจจะเน็ตเวิร์ก | pvecm status |
| GUI ช้า | CPU หรือ I/O pressure | pveperf |
สรุป Metrics สำคัญ
| Layer | Metric | ตรวจด้วย | ค่าเหมาะสม |
|---|---|---|---|
| Host | CPU / IO Delay / Memory | pveperf | IO Delay <5% |
| Storage | Latency / IOPS | zpool iostat ถ้าใช้ ZFS | SSD <5ms |
| VM | CPU / Memory / Disk IO | GUI / qm status | ขึ้นกับ workload |
| Cluster | Quorum / Latency | pvecm status | Quorum = Yes |
| PSI | CPU / Memory / IO stall | /proc/pressure | avg10 <10% |
คำแนะนำเพื่อเพิ่มประสิทธิภาพ Proxmox VE 9
- ใช้ SSD หรือ NVMe สำหรับ VM disks
- เพิ่ม SLOG แยก สำหรับ workload ที่มี sync write สูง
- เปิด ZFS compression (lz4)
- จำกัดจำนวน backup หรือ replication พร้อมกัน
- ใช้ virtio-scsi + iothreads
- ตั้ง scheduler ของ SSD เป็น
none
ตัวอย่าง
echo none > /sys/block/sdX/queue/scheduler
เมื่อ sdX คือ ชื่อ device name สำหรับ disk ที่ต้องการจะทำการแก้ไข scheduler
ข้อสรุป
Proxmox VE 9 ให้ความสามารถในการตรวจสอบ
- Host
- VM
- Storage
ได้อย่างละเอียด
แต่การเข้าใจ metrics เหล่านี้ เป็นกุญแจสำคัญในการรักษา cluster ให้
- มีความเสถียร
- ตอบสนองเร็ว
- มีประสิทธิภาพสูงเท่าที่จะเป็นไปได้
การ monitor ค่าเช่น
- I/O pressure
- CPU load
- ZFS latency
จะช่วยให้คุณ
- ตรวจพบปัญหาได้เร็ว
- วางแผน upgrade hardware
- ทำให้ infrastructure ทำงานได้อย่างมีประสิทธิภาพในระยะยาว
สนใจวางระบบด้วย Proxmox VE ไม่ว่าจะเป็น คลัสเตอร์หรือว่า Standalone หรืองาน Migrate พูดคุยปรึกษาเราได้ทันที ที่ Line OA : @avesta.co.th หรืออีเมล์ [email protected] เราพร้อมให้บริการตลอดเวลา ทุกภูมิภาคทั่วไทย
Tailscale Subnet Routers

MinIO vs Garage S3 vs Ceph RGW
Proxmox VE Cluster Resource Scheduling

Introduction to Data Leak Prevention
Proxmox Ecosystem